
Kirit Thadaka
· Machine learning
· Data visualization
· Predictive analysis
· Voice assistants

I’ll illustrate an example of how easy it is to get started with data science using Python. Here’s a simple example of how you can use Scikit-Learn for some meaningful data analysis.
July 29, 2019
What is data science?
How often do you think you’re touched by data science in some form or
another? Finding your way to this article likely involved a whole bunch of data
science (whooaa). To simplify things a bit, I’ll explain what data science
means to me.
“Data Science is the art of applying scientific methods of analysis to
any kind of data so that we can unlock important information.”
That’s a mouthful. If we unpack that, all data science really means is
to answer questions by using math and science to go through data that’s too
much for our brains to process.
Data Science covers…
· Data visualization
· Predictive analysis
· Voice assistants
… and all the buzzwords we hear today, like artificial intelligence,
deep learning, etc.
To finish my thought on data science being used to find this article,
I’ll ask you to think of the steps you used to get here. For the sake of this explanation,
let’s assume that most of you were online looking at pictures of kittens and
puppies when you suddenly came across a fancy word related to data science and
wanted to know what it was all about. You turned to Google hoping to find the
meaning of it all, and you typed “What is *fill in your data science related
buzzword*.”
You would have noticed that Google was kind enough to offer suggestions
to refine your search terms – that’s predictive text generation. Once the
search results came up, you would have noticed a box on the right that
summarizes your search results – that’s Google’s knowledge graph. Using
insights from SEO (Search Engine Optimization) I’m able to make sure my article
reaches you easily, which is a good data science use case in and of itself. All
of these are tiny ways that data science is involved in the things we do every
day.
To be clear, going forward I’m going to use data science as an umbrella
term that covers artificial intelligence, deep learning and anything else you
might hear that’s relevant to data and science.
Positives: astrophysics, biology, and sports
Data science made a huge positive impact on the way technology
influences our lives. Some of these impacts have been nice and some have been
otherwise. *looks at Facebook* But, technology can’t inherently be good or bad,
technology is… technology. It’s the way we use it that has good or bad
outcomes.
We recently had a breakthrough in astrophysics with the first ever
picture of a black hole. This helps physicists confirm more than a century of
purely theoretical work around black holes and the theory of relativity.
To capture this image, scientists used a telescope as big as the earth
(Event Horizon Telescope or EHT) by combining data from an array of eight
ground-based radio telescopes and making sense of it all to construct an image.
Analyzing data and then visualizing that data – sounds like some data science
right here.
A cool side note on this point: a standard Python library of functions
for EHT Imaging was developed by Andrew Chael from Harvard to simulate and
manipulate VLBI (Very-long-baseline interferometry) data helping the process of
creating the black hole image.
Olivier Elemento at Cornell uses Big Data Analytics to help identify
mutations in genomes that result in tumor cells spreading so that they can be
killed earlier – this is a huge positive impact data science has on human life.
You can read more about his incredible research here.
Python is used by researchers in his lab while testing statistical and
machine learning models. Keras, NumPy, Scipy, and Scikit-learn are some top
notch Python libraries for this.
If you’re a fan of the English Premier League, you’ll appreciate the
example of Leicester City winning the title in the 2015-2016 season.
At the start of the season, bookmakers had the likelihood Leicester City
winning the EPL at 10 times less than the odds of finding the Loch Ness
monster. For a more detailed attempt at describing the significance of this
story, read this.
Everyone wanted to know how Leicester was able to do this, and it turns
out that data science played a big part! Thanks to their investment into
analytics and technology, the club was able to measure players’ fitness levels
and body condition while they were training to help prevent injuries, all while
assessing best tactics to use in a game based on the players’ energy levels.
All training sessions had plans backed by real data about the players,
and as a result Leicester City suffered the least amount of player injuries of all
clubs that season.
Many top teams use data analytics to help with player performance,
scouting talent, and understanding how to plan for certain opponents.
Here’s an example of Python being used to help with some football
analysis. I certainly wish Chelsea F.C. would use some of these techniques to
improve their woeful form and make my life as a fan better. You don’t need
analytics to see that Kante is in the wrong position, and Jorginho shouldn’t be
in that team and… Okay I’m digressing – back to the topic now!
Now that we’ve covered some of the amazing things data science has
uncovered, I’m going to touch on some of the negatives as well – it’s important
to critically think about technology and how it impacts us.
The amount that technology impacts our lives will undeniably increase
with time, and we shouldn’t limit our understanding without being aware of the
positive and negative implications it can have.
Some of the concerns I have around this ecosystem are data privacy (I’m
sure we all have many examples that come to mind), biases in predictions and
classifications, and the impact of personalization and advertising on society.
Negatives: gender bias and more
This paper published in NIPS talks about how to counter gender biases in
word embeddings used frequently in data science.
For those who aren’t familiar with the term, word embeddings are a
clever way of representing words so that neural networks and other computer
algorithms can process them.
The data used to create Word2Vec (a model for word embeddings created by
Google) has resulted in gender biases that show close relations between “men”
and words like “computer scientist”, “architect”, “captain”, etc. while showing
“women” to be closely related to “homemaker”, “nanny”, “nurse”, etc.
Here’s the Python code used by the researchers who published this paper.
Python’s ease of use makes it a good choice for quickly going from idea to
implementation.
It isn’t always easy to preempt biases like these from influencing our
models. We may not even be aware that such biases exist in the data we collect.
It is imperative that an equal focus is placed on curating, verifying,
cleaning, and to some extent de-biasing data.
I will concede that it isn’t always feasible to make all our datasets
fair and unbiased. Lucky for us, there is some good research published that can
help us understand our neural networks and other algorithms to the extent that
we can uncover these latent biases.
When it comes to data science, always remember –
“Garbage in, garbage out.”
The data we train our algorithms with influences the results they
produce. The results they produce are often seen by us and can have a lasting
influence.
We must be aware of the impact social media and content suggestions have
on us. Today, we’re entering a loop where we consume content that reinforces
our ideas and puts people in information silos.
Research projects that fight disinformation and help people break out of
the cycle of reinforcement are critical to our future. If you were trying to
come up with a solution to this fake news problem, what would we need to do?
We would first need to come up with an accurate estimate of what
constitutes “fake” news. This means comparing an article with reputable news
sources, tracing the origins of a story, and verifying that the article’s
publisher is a credible source.
You’d need to build models that tag information that hasn’t been
corroborated by other sources. To do this accurately, one would need a ton of
not “fake” news to train the model on. Once the model knows how to identify if
something is true (to a tolerable degree of confidence), then the model can
begin to flag news that’s “fake.”
Crowd sourced truth is also a great way to tackle this problem, letting
the wisdom of the crowd determine what the “truth” is.
Blockchain technology fits in well here by allowing data to flow from
people all over the world and arrive at consensus on some shared truth.
Python is the fabric that allows all these technologies and concepts to come
together and build creative solutions.
Python, a data science toolset
I’ve talked about data science, what it means, how it helps us, and how
it may have negative impacts on us.
You’ve seen through a few examples how Python is a versatile tool that can
be used across different domains, in industry and academia, and even by people
without a degree in Computer Science.
Python is a tool that makes solving difficult problems a little bit
easier. Whether you’re a social scientist, a financial analyst, a medical
researcher, a teacher or anyone that needs to make sense of data, Python is one
thing you need in your tool box.
Since Python is open source, anyone can contribute to the community by
adding cool functionalities to the language in the form of Python libraries.
Data visualization libraries like Matplotlib and Seaborn are great for
representing data in simple to understand ways. NumPy and Pandas are the best
libraries around to manipulate data. Scipy is full on scientific methods for
data analysis.
Whether you want to help fight climate change, analyze your favorite
sports team or just learn more about data science, artificial intelligence, or
your next favorite buzzword – you’ll find the task at hand much easier if you
know some basic Python.
Here are some great Python libraries to equip yourself with:
- NumPy
- Pandas
- Scikit-Learn
- Keras
- Matplotlib
I’ll illustrate an example of how easy it is to get started with data science using Python. Here’s a simple example of how you can use Scikit-Learn for some meaningful data analysis.
Python example with Scikit-learn
This code is available at the Kite
Blog github repository.
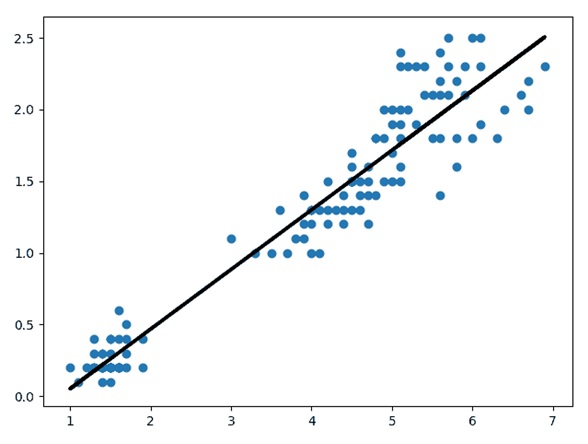
I’ve used one of Scikit-Learn’s datasets called Iris, which is a dataset
that consists of 3 different types of irises’ (Setosa, Versicolour, and
Virginica) petal and sepal length, stored in a 150×4 numpy.ndarray. The rows
are the samples and the columns are: Sepal Length, Sepal Width, Petal Length,
and Petal Width.
I’m going to run a simple linear regression to display the correlation
between petal width length. The only libraries used here are scikit-learn (for
the regression and data set) and matplotlib for the plotting.
from sklearn import datasets, linear_model
import matplotlib.pyplot as plt
iris = datasets.load_iris()
# Data and features are both numpy arrays
data = iris.data
features = iris.feature_names
Now, we’ll plot a linear regression between the length and width of the
petals to see how they correlate.
# Create the regression model
regression = linear_model.LinearRegression()
# Reshape the Numpy arrays so that they are columnar
x_data = data[:, 2].reshape(-1, 1)
y_data = data[:, 3].reshape(-1, 1)
# Train the regression model to fit the data from iris (comparing the
petal width)
regression.fit(x_data, y_data)
# Display chart
plt.plot(x_data, regression.predict(x_data), color='black', linewidth=3)
plt.scatter(x_data, y_data)
plt.show()
Here’s a tutorial I created to learn NumPy, and here’s a notebook that
shows how Keras can be used to easily create a neural network. Just this much
will allow you to build some pretty cool models.
Concluding thoughts
Before I end, I’d like to share some of my own ideas of what I think the
future of data science looks like.
I’m excited to see how concerns over personal data privacy shapes the
evolution of data science. As a society, it’s imperative that we take these
concerns seriously and have policies in place that prevent our data
accumulating in the hands of commercial actors.
When I go for walks around San Francisco, I’m amazed at the number of
cars I see with 500 cameras and sensors on them, all trying to capture as much
information as they possibly can so that they can become self driving cars. All
of this data is being collected, it’s being stored, and it’s being used. We are
a part of that data.
As we come closer to a future where self driving cars become a bigger
part of our life, do we want all of that data to be up in the cloud? Do we want
data about the things we do inside our car available to Tesla, Cruise or
Alphabet (Waymo)?
It’s definitely a good thing that these algorithms are being trained
with as much data as possible. Why would we trust a car that hasn’t been
trained enough? But that shouldn’t come at the cost of our privacy.
Instead of hoarding people’s personal data in “secure” cloud servers,
data analysis will be done at the edge itself. This means that instead of
personal data leaving the user’s device, it will remain on the device and the
algorithm will run on each device.
Lots of development is happening in the field of Zero Knowledge
Analytics which allows data to be analyzed without needing to see what that
data is. Federated Learning allows people to contribute to the training of
Neural Networks without their data to leaving their device.
The convergence of blockchain technology and data science will lead to
some other exciting developments. By networking people and devices across the
globe, the blockchain can provide an excellent platform for distributed
computation, data sharing, and data verification. Instead of operating on
information in silos, it can be shared and opened up to everyone. Golem is one
example of this.
Hypernet is a project born out of Stanford to solve a big problem for
scientists – how to get enough compute power to run computationally and data
intensive simulations.
Instead of waiting for the only computer in the university with the
bandwidth to solve the task and going through the process of getting permission
to use it, Hypernet allows the user to leverage the blockchain and the large
community of people with spare compute resources by pooling them together to
provide the platform needed for intensive tasks.
Neural networks for a long time have felt like magic. They do a good
job, but we’re not really sure why. They give us the right answer, but we can’t
really tell how. We need to understand the algorithms that our future will be
built on.
According to DARPA, the “third-wave” of AI will be dependent on
artificial intelligence models being able to explain their decisions to us. I
agree, we should not be at the mercy of the decisions made by AI.
I’m excited with what the future holds for us. Privacy, truth, fairness,
and cooperation will be the pillars that the future of data science forms on.
Fuente: https://kite.com/blog/python/future-of-data-science/
About Kirit Thadaka: https://kirit93.github.io/
About Kirit Thadaka: https://kirit93.github.io/